The position estimation of objects in images is usually implemented
by multi-layer convolutional neural networks, which final layer is a
linear function. These networks often support scale-invariance, due to
the convolution layers.
For very basic applications, such an approach can be more than needed
and lead to a long training time and high memory consumption.
If scale invariance is not needed, the following approach can be used
to create a one-layer object position detection neural network. The
input images are processed as follows:
Apply a Sobel filter.
Apply a convolutional layer, ReLU and divide by the maximum
value.
Raise the values of the output to the power of 5 or a higher
number.
Normalize the output.
Calculate the expected value of the image.
(Note, that some steps have been omitted to provide a simpler
explanation)
Steps 2 to 4 will enforce that the output is a probability
distribution. Due to the exponentiation in step 3, the maximum will
remain while local minimia will disappear.
The following picture shows a test picture (original is from Urlaubsguru.de).
Ten smiley faces have been added to a background image. The model was
trained to find the only happy face on this image.
Original picture
The next picture shows the output of step 2.
Output of step 2
The last picture shows the output of step 4.
Output of step 4
In a training with 30 images with the Adam optimizer, this approach
converges after about 50 epochs, which shows that this method is
suitable for this task.
Transitioning
an Application from On-Premises to Azure Docker Containers
In a previous blog post, I discussed the process of migrating an on-premises
application to an Azure Scale Set. Recently, I had again the
opportunity to transition an existing .NET background service to Azure
using docker. A key distinction between the previously migrated
application and the one targeted for this migration was its lack of
Windows dependencies. This meant that the application could be feasibly
migrated to a Docker container.
Starting with docker
containers
Despite my limited experience with Docker containers, I was eager to
delve deeper and expand my knowledge. I immersed myself in numerous
documentation resources to understand how to create a Docker container
using a Dockerfile.
Most examples
demonstrated the use of a Linux base image and the building of the
application using the .NET CLI like the following:
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build-envWORKDIR /App# Copy everythingCOPY . ./# Restore as distinct layersRUNdotnet restore# Build and publish a releaseRUNdotnet publish -c Release -o out# Build runtime imageFROM mcr.microsoft.com/dotnet/aspnet:8.0WORKDIR /AppCOPY--from=build-env /App/out .ENTRYPOINT ["dotnet", "DotNet.Docker.dll"]
The private nuget feed
problem
The above Dockerfile works great for applications that do not have
dependencies on private nuget feeds. However, as you might have
anticipated, the application targeted for migration did rely on a
private NuGet feed. One potential workaround for this predicament would
be to incorporate the credentials for the private NuGet feed directly
into the Dockerfile. There are different ways to accomplish this, one of
them can be read here Consuming
private NuGet feeds from a Dockerfile in a secure and DevOps friendly
manner.
While this approach might seem straightforward, it’s not without its
drawbacks. Apart from the glaring security implications, the process of
making these adjustments can be quite cumbersome.
Fortunately, the .NET CLI comes to the rescue, offering support for
building Docker images with the command
dotnet publish --os linux --arch x64 /t:PublishContainer -c Release.
The Docker image was constructed within a CI/CD pipeline, an environment
already authenticated and granted access to the private NuGet feed. As a
result there was no need for additional configuration.
Please notice if you want to create a docker image based on the
alpine image, you need to specify the correct runtime identifier (RID)
for the alpine image, otherwise you will not be able to start the
application. You can find the RIDs here: RID
catalog and more about the issue here.
You may have noticed in the above build pipeline that we are using
the dotnet publish /t:PublishContainer command. This
command builds and publishes the Docker image to the local Docker
repository. While this is excellent for local development, it raises
questions about handling multiple environments and the appsettings.json
file.
To address this, we save the local published Docker image into the
DotNetDockerTemp.tar file and add it to the artifacts of
the build pipeline (see 1. Code snippet from the build pipeline). During
the release pipeline, we download the artifact and load the Docker image
into the local Docker repository using the
docker load -i DotNetDockerTemp.tar command.
Next, we tackle the appsettings.json file. For this, we
require the FileTransform@1 task, which transforms the
appsettings.json file based on the environment. While we
can’t inject the appsettings.json file into the existing
Docker image DotNetDockerTemp:latest, we can create a new
Docker image based on the existing one.
Finally, as a last step, we could push the docker image to the Azure
Container Registry.
Custom DNS and SSL
Certificates
Upon starting the Azure Container Instance (ACI), I discovered that
the service was unable to access certain endpoints. After conducting
some investigations, connecting to the container instance with
az container exec (or using the azure portal) and probing
with nslookup and related commands, I deduced that the
Docker container instance was incapable of resolving our custom domain
names. This is understandable, as the Docker container instance does not
know our custom DNS server. This issue can be resolved by configuring
the dnsConfig for your ACI.
With the updated settings, the app was able to resolve the endpoint
but encountered an exception due to an invalid SSL certificate. Once
again, this is logical as the Docker container instance is unaware of
our custom SSL certificate. To enable the app or the operating system to
accept the custom certificate of our endpoint, we need to add the public
key of the certificate to the trusted root certificates of the Docker
container instance. I was unable to find a method to accomplish this
within the pipeline using the Docker command line. Consequently, I opted
to create a custom Docker image based on the existing one and add the
public key of the certificate to the trusted root certificates of the
Docker container instance.
FROM DotNetDockerTemp:latest AS baseWORKDIR /app# Second stage: Use the Alpine imageFROM mcr.microsoft.com/dotnet/runtime:8.0-alpine AS finalUSER $APP_UIDWORKDIR /app# Copy files from the first stageCOPY--from=base /app /appUSER rootCOPY ["certificate.crt", "/usr/local/share/ca-certificates/"]RUNapk add --no-cache ca-certificatesRUNupdate-ca-certificatesUSER $APP_UIDENTRYPOINT ["/app/DotNetDocker"]CMD ["-s"]
This dockerfile use the docker image which was previously created
with the dotnet publish /t:PublishContainer [...] command
and add the public key of the certificate to the trusted root
certificates of the docker container instance. Since the app
DotNetDocker needs to be started with DotNetDocker -s we
need to add the -s to the CMD command. To build the docker
image using the dockerfile we can use the following command:
.: Path to the context; current directory where docker buildx build
is executed (important for the COPY command)
-t: Tag of the docker image
–no-cache: Do not use cache when building the image
–progress=plain: Show the progress of the build
Wrapping Up
Transitioning the application into a Docker container proved to be a
swift and straightforward process. However, it’s important to note that
this journey can entail numerous considerations that may demand a
significant investment of time, particularly when the source code of the
application is not open to modifications.
I’m eager to hear your thoughts on this process. Would you have
approached it differently? Do you have any queries or insights to share?
Your feedback is invaluable, and I look forward to our continued
discussions on this topic.
To set the stage, let’s first delve into the context and requirements
of our scenario. Our clientele primarily utilizes our application during
a specific recurring time frame in the afternoon to streamline their
business operations. The application was hosted on-premises on a limited
number of static machines.
While it’s possible to horizontally scale the application by
incorporating additional machines, this approach has its limitations. It
requires significant manual intervention and lacks the flexibility to
adapt to fluctuating demand. This is where Azure Scale Sets come into
play.
Azure Scale set is a group of identical, scaling VMs when using
Orchestration mode Uniform (optimized for large scale stateless
workloads with identical instances). Which means, you cannot have in
your scale set virtual machines with different hardware specifications.
There is also the option flexible: achieve high availability at scale
with identical or multiple virtual machine types.
Since the on-premise machines should be decommissioned soon, we
decided to migrate the application to Azure. The application has some
dependencies to the Windows operating system and is not yet ready to be
containerized. This was the main reason why we had to choose Azure Scale
Sets over azure Kubernetes.
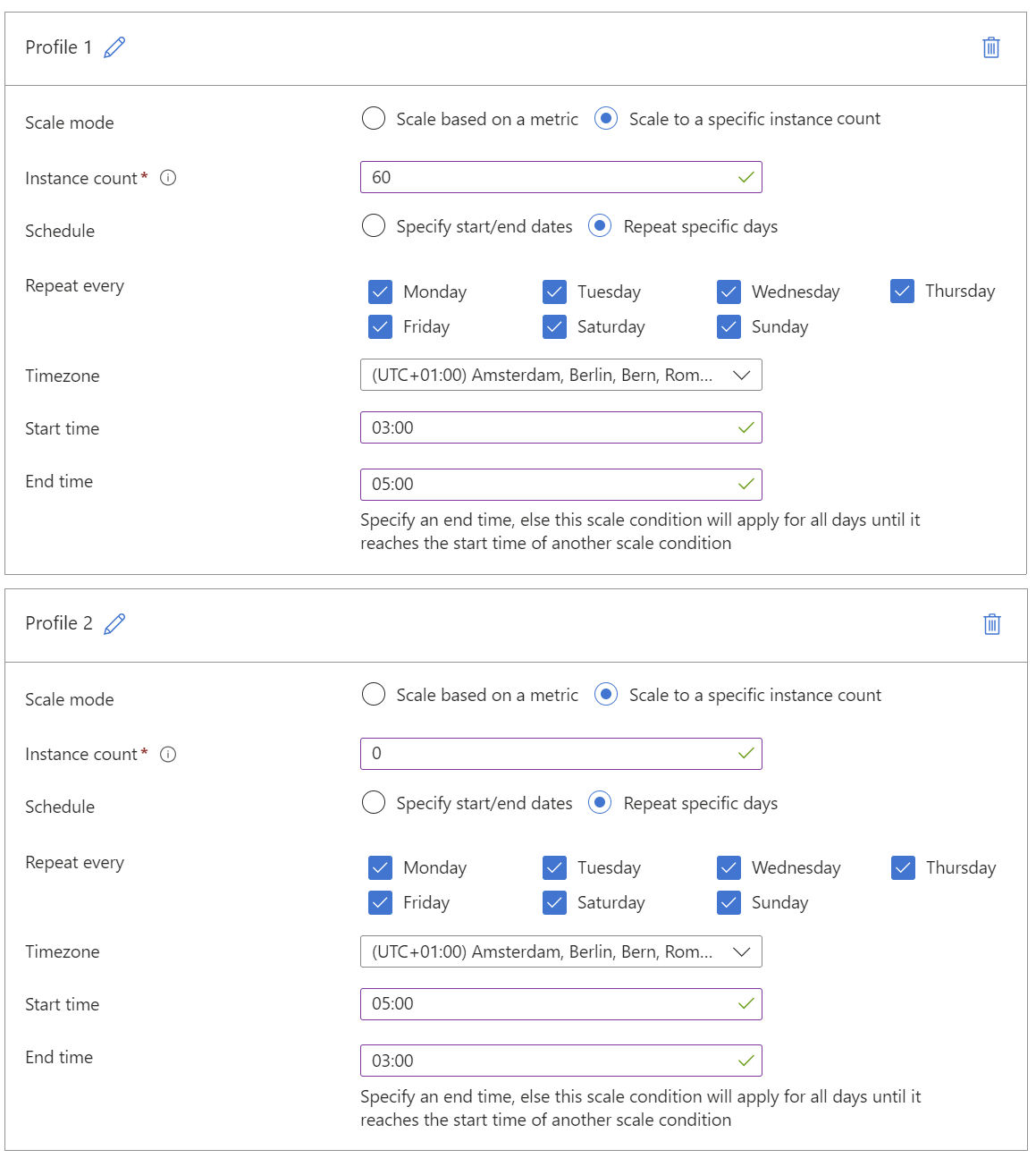
Scaling
There are different scaling types:
Manual scaling
define manual how many VMs you want to have in your scale set
(Fig 1. manual scaling)
Time based scaling
You can define a schedule to scale up or down the number of VMs in
the scale set. This is useful if you know the demand for your
application will increase or decrease at specific times.
(Fig 2. time based scaling)
Metric based scaling (CPU, Memory, Network, Disk I/O, etc.)
This is provided out of the box. Each VM in the scale set will have
a metric agent installed that will send the metrics to Azure
Monitor.
Log based scaling (Application logs, Event logs, etc.)
For this you need to customize your app and write specific logs or
metrics, which can be than used to scale the VMs. For example, you could
track the number of business cases that needs to be processed and scale
the VMs based on that.
Considering the substantial costs associated with running multiple
VMs, log-based scaling could be an optimal choice. This is because CPU
and memory metrics may not always accurately indicate the necessary
number of instances. However, implementing log-based scaling could be
quite labor-intensive. As we preferred not to modify the application and
knew that our application’s demand would fluctuate at specific times, we
opted for time-based scaling.
Application
deployment within the scale set
Now the question is, how do we get the application to the virtual
machine’s instances in the azure scale set? First you need to find a
proper base image for the VMs. We use a base image provided by microsoft
with 1GB RAM and 1 CPU as this was sufficient for our application. Base
images with more RAM and CPU are also available but they are more
expensive. Keep in mind, that the azure web portal does not provide all
base images. You can find more base images using the azure cli.
The most straightforward method to install your application onto the
VM involves storing the application in a blob storage and downloading it
during the VM creation. But how do we achieve this?
This is really straight forward. From the azure portal you can
select from an existing blog storage a powershell script which will be
executed during the VM creation. This script can be used to download the
application from the blob storage and install it on the VM. Bear in mind
that the script will be executed only once during the VM creation. If
you want to update the application, you need to create a new VM. Also,
if you install a lot of software on the VM, the VM creation will take a
lot of time. This brings us to the third option.
Custom Image
You create your own image with all the software you need. Using the
custom image for the VMs your application would be much sooner ready
compared to the Azure custom Script Extension approach. Building such an
image can take a lot of time and you also would need some staging
environment to test the images. Also, you probably need to update the
image from time to time. This would not be necessary if you use the
provided Microsoft base images as they contain always the latest hot
patches.
In our scenario the Azure Custom Script Extension was the best
option, as it seems to be straight forward, and we didn’t need to
install a lot of software on the VMs. The final solution consisted of a
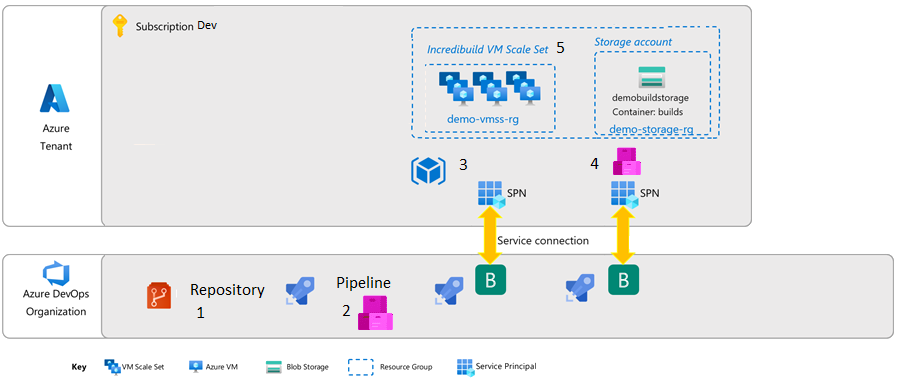
resource group with the following resources:
Storage account
contain a PowerShell script which is downloading the application as
zip file from the blob storage and installing it on the VM
the application itself as zip file
Azure Scale Set as Managed Identity which can access the storage
account using its system assigned identity
Application Insights (which is used by the application)
Final Picture
(Fig 3. Architecture Azure Scale
Set)
The application which should be hosted in the azure scale set already
had a CICD pipeline. The pipeline was extended and modified in a way
with the following steps:
build the application
create a zip file containing the application (see image above
2)
create an additional artifact containing the powershell script which
is used to setup the VMs (see image above 2)
create and deploy the required azure infrastructure (Azure Scale Set
storage account) using IaC (see image above 3)
upload the artifacts from step 2 and 3 to the storage account
IaC (Infrastructure as Code)
Our Azure infrastructure was successfully deployed using a YAML
pipeline, specifically utilizing the
AzureResourceManagerTemplateDeployment task. This task
allows us to define a template, using either an ARM or Bicep file, to
create the necessary Azure resources.
As part of this process, we deployed a new subnet within an existing
virtual network. This virtual network establishes a connection between
Azure and our on-premise network. This newly created subnet is then
utilized within the Azure scale set.
Each instance generated by the Azure scale set will automatically
adopt an IP address from our defined subnet. Therefore, it’s essential
to consider the number of instances you’ll need for your resources
upfront, as this will influence the subnet definition.
To enhance flexibility during the Infrastructure as Code (IaC)
deployment, we incorporated parameters into the template. These
parameters allow for easy adjustments to the Azure resources. For
instance, within the parameter section, one can define the subnet range
or the base image for the Azure scale set.
Additionally, the IaC template outputs certain values, such as the
created resource group, storage account, the URL of blob storage, the
container names of the storage account and other data which is required
later for uploading for example the artifact to the storage account.
Also these outputs can be particularly useful for debugging during the
template creation process.
CustomScriptExtension
& Storage Account
The deployment of IaC templates is designed to be incremental. This
implies that if you modify the IaC template and redeploy it, only the
changes will be implemented. However, this process doesn’t always go as
planned, and you might encounter a deployment failure with an
uninformative error message. In such scenarios, you’ll need to delete
the resource group and redeploy the IaC template.
This issue often arises when changes are made to the
commandToExecute within the
CustomScriptExtension. This commandToExecute
is a PowerShell script that is executed during the VM’s creation.
Furthermore, alterations to the storage account permissions or Azure
scale set properties like
osProfile.windowsConfiguration.timezone may require the
removal of Azure resources and a redeployment of the IaC template. If
these changes are made, the deployment may fail, returning an error
message:
{"code":"DeploymentFailed","message":"At least one resource deployment operation failed. Please list deployment operations for details.","details":[{"code":"PropertyChangeNotAllowed","target":"windowsConfiguration.timeZone","message":"Changing property 'windowsConfiguration.timeZone' is not allowed."}]}.
Now, let’s return to the discussion on how the
CustomScriptExtension and the storage account interact.
To begin with, we’ve configured the storage account and its container
to restrict access solely to Azure Managed Identities with the
Storage Blob Data Reader role. This ensures that the hosted
files are secure and inaccessible to unauthorized entities.
The Azure scale set, equipped with a system-assigned identity, is
granted access to the storage account via the
Storage Blob Data Reader role. With this setup in place, we
can attempt to download the artifacts from the storage account using a
VM within the Azure scale set for testing purposes.
Our ultimate goal is to download these artifacts, which include the
PowerShell install script, during the VM creation process.
In theory, the CustomScriptExtension should support the
direct downloading of artifacts from a storage account. An example of
this can be found here.
However, I suspect that our storage account’s restriction policy might
have hindered this functionality. As a result, I implemented a
workaround, which involves acquiring an access token from the Azure
scale set to access the storage account.
For guidance on how to do this, refer to “Acquire
an access token”. This process is similar to the token
acquisition for App Registrations. However, I tried to simplify the
process of acquiring the access token, downloading the install script,
and executing it on the VM into a single command. This was necessary
because the commandToExecute in the
CustomScriptExtension is designed to execute only one
command.
Each time a new instance is initiated, a virtual machine (VM) is
created using the base image specified in the Azure scale set (for
instance, a datacenter-azure-edition-core-smalldisk image).
Thanks to the CustomScriptExtension, the Windows image
includes a Windows service installed in
(C:\Packages\Plugins\Microsoft.Compute.CustomScriptExtension\).
This service executes the commandToExecute of the
CustomScriptExtension. In our case we should find the
script at
C:\Packages\Plugins\Microsoft.Compute.CustomScriptExtension\1.9.5\Downloads\1\{YourPowershellInstallScriptOnVmCreation}.ps1.
You can verify this by connecting to the VM via Remote Desktop Protocol
(RDP).
The 1.status file, located in
C:\Packages\Plugins\Microsoft.Compute.CustomScriptExtension\1.9.5\Status,
should contain the output of the
{YourPowershellInstallScriptOnVmCreation}.ps1 script when
executed.
The logs of the CustomScriptExtension can be found in
C:\WindowsAzure\Logs\Plugins\Microsoft.Compute.CustomScriptExtension\1.9.5\.
The powershell script
YourPowershellInstallScriptOnVmCreation.ps1 itself is
downloading the application from the storage account and installing it
on the VM.
Please check ochzhen.com
blog for more information about the CustomScriptExtension.
Uploading the
artifacts to the storage account
Once the Infrastructure as Code (IaC) template is deployed, the next
step is to upload the artifacts (the application and PowerShell script)
to the storage account. To do this, we first need the storage account’s
URL. Fortunately, we’ve already included the resource group name and
storage account name, among other details, in the output of the IaC
template deployment.
In the Azure pipeline, we can access the output of the IaC template
deployment using the $(ArmOut_rgName) syntax. This can be
accomplished using the Azure CLI. The script below demonstrates how to
upload the artifacts to the storage account:
[...]jobs:-job: deploymentdisplayName:'Upload Script & Application'dependsOn: DeployIaCvariables:-name:'storageAccountName'value: $[dependencies.DeployIaC.outputs['outputVars.storageAccountName']]-name:'rgName'value: $[dependencies.DeployIaC.outputs['outputVars.rgName']][... download artifacts]-task: AzureCLI@2displayName:'Upload Script'inputs:azureSubscription:scriptType:'pscore'scriptLocation:'inlineScript' inlineScript: | az config set extension.use_dynamic_install=yes_without_prompt az storage azcopy blob upload -c "{YourPowershellInstallScriptOnVmCreation}.ps1" --account-name $(storageAccountName) -s $(Pipeline.Workspace)/Scripts/{YourPowershellInstallScriptOnVmCreation}.ps1
Upgrade policy
The upgrade policy defines how the VMs in the scale set are updated.
There are three options:
Manual
Automatic
Rolling
At present, we employ the Manual upgrade policy as our
VMs are created daily and operate within a specific timeframe. After
this timeframe, all VMs are removed. Consequently, new VMs are
recreated, and the application is reinstalled the following day. This
approach guarantees that the application remains updated.
If your application operates continuously and frequently receives
updates, you might want to consider an upgrade policy other than
Manual. In the azure scale set select
Instances to check the state of the VMs.
(Fig 4. instances)
If you see a warning sign in the column Latest model you
would need to reimage the selected instance to have the VM
in the latest state with the latest application version.
However when uploading a new version of your application to the
storage account, within the azure pipeline you would need to
reimage all VMs in the scale set. This can be done using
the azure cli: az vmss update-instances
Summary
In conclusion, Azure Scale Sets provide a powerful and flexible
solution for managing and scaling applications. By leveraging features
like time-based scaling, Custom Script Extensions, and Managed
Identities, we were able to create a system that adapts to our
application’s specific needs and usage patterns. Remember, the choice of
upgrade policy and scaling type should align with your application’s
requirements and operational patterns. I’ll be sure to update this
article as we continue to explore Azure Scale Sets and their
capabilities.
Recently, I embarked on a quest to install Linux on my Surface Pro 4.
I followed several installation guides specifically tailored for Surface
Pro devices. These guides suggested creating a bootable Linux USB,
adjusting the UEFI Settings to select either “None” or “Microsoft &
3d-party CA”, and modifying the boot order accordingly.
Despite my best efforts, my Surface Pro 4 refused to boot from the
USB and would always default to starting Windows. The cause of this
behavior remains a mystery to me. I experimented with various setups,
including using different USB sticks and employing different
applications to create the bootable Linux USB. However, none of these
attempts bore fruit. Even when I accessed GRUB, the bootloader used by
Linux, the USB stick was nowhere to be found.
The journey continues as I seek a solution to this intriguing
challenge. The goal remains: successfully booting Linux on my Surface
Pro 4.
Installing grub2win
Given the persistent issue with the UEFI Settings not loading my USB
Linux setup, I decided to install Grub2Win and attempt to load my Linux
setup from there. I installed Grub2Win on my
Windows machine and disabled the “Microsoft only” option in the UEFI
settings under security.
Upon booting into Grub2Win, pressing c opens a bash-like
terminal. Using ls displays all existing partitions
recognized by Grub. However, Grub also failed to recognize my USB
stick.
Create linux setup partition
Given the persistent issues with the USB media, I decided to pivot my
approach and use my internal hard disk drive as the installation source.
To accomplish this, I first booted into Windows and launched the Disk
Management tool using the diskmgmt.msc command.
In the Disk Management interface, I created a new partition on my
main hard disk drive and formatted it to FAT32. This new partition would
serve as the destination for my Linux setup files.
Next, I copied the content of the USB media to this newly created
partition. In my case, this involved extracting the Linux
.iso file directly onto the partition.
With the setup files in place, I rebooted my system to Grub2Win,
ready to proceed with the Linux installation from the hard disk
drive.
Identifying the
Linux Setup Partition in Grub
Armed with the ls command, I set out to identify the
partition label (hd0,gptx) corresponding to the newly
created partition housing my Linux setup files. Knowing the specific
folders and files that comprise the Linux setup media can be incredibly
helpful in this process.
To locate these files, I executed a series of commands:
ls (hd0,gpt7), ls (hd0,gpt6), and so forth. I
continued this process until I encountered folders and files that I
recognized as part of the Linux setup media.
Once I had identified the correct partition label, I executed the
command set root=(hd0,gpt4). This was followed by
chainloader /efi/boot/grubx64.efi and boot.
These commands instructed Grub to load the Linux setup from the
specified partition.
At long last, my Linux setup loaded successfully, and I was able to
install Linux on my Surface Pro 4.
The full grub command history can be found here
GNU GRUB version 2.06Minimal BASH- like line editing is supported. For the first word, TAB lists possible command completions. Anywhere else TAB lists possible device or file completions. ESC at any time exits.grub> ls(hd0)(hd0 ,gpt7)(hd0 ,gpt6)(hd0 ,gpt5)(hd0 ,gpt4)(hd0,gpt3)(hd0 ,gpt2)(hd0,gpt1)grub> ls (hd0 ,gpt7)error: unknown filesystem.grub> ls (hd0,gpt6)/ lost+found/ boot/ etc/ media/grub> ls (hd0,gpt5)/$AttrDef$BadClus$Bitmap$B00t$Extend/ $LogFile$MFT$MFTMirr$Secure$UpCase$Volume Recovery/ System volume Information/grub> ls (hd0,gpt4)/System Volume Information/ efi/ README.html README.mirrors.html README.mirrors.txt README.source readme.txt autorun.inf boot/ css/ dists/ doc/ firrmuare/ g21dr g21dr.rnbr install/ install.amd/ isolinux/ md5sum.txt pics/ pool/ setup.exe tools/ win32-loader.ini [BOOT]/ $recycle.bin/grub> set root=(hd0,gpt4)grub> chainloader /efi/boot/grubx64.efi/EndEntirefile path: /ACPI(a0341d0,0)PCI(0,1c)/PCI(0,0)/UknownMessaging(17)HD(4 , 133e8000 , 108fOOO , b68981S490382e41 , 2 , 2)File(\efi\boot)/File(grubx64.efi)/EndEntiregrub>boot
After the linux setup is complete one can delete the temporary
created linux setup partition.
As part of my ongoing efforts to enhance security and streamline
processes, I’ve embarked on a project to migrate my credentials to Azure
Key Vault. This move is a significant step towards centralizing and
securing sensitive data. I’ve already made substantial progress, having
established a service connection in Azure DevOps to Azure. You can learn
more about this process in my previous post, see
here.
For my legacy build pipelines I stored my certificates and secrets
under Library / Variable groups and
Secure files.
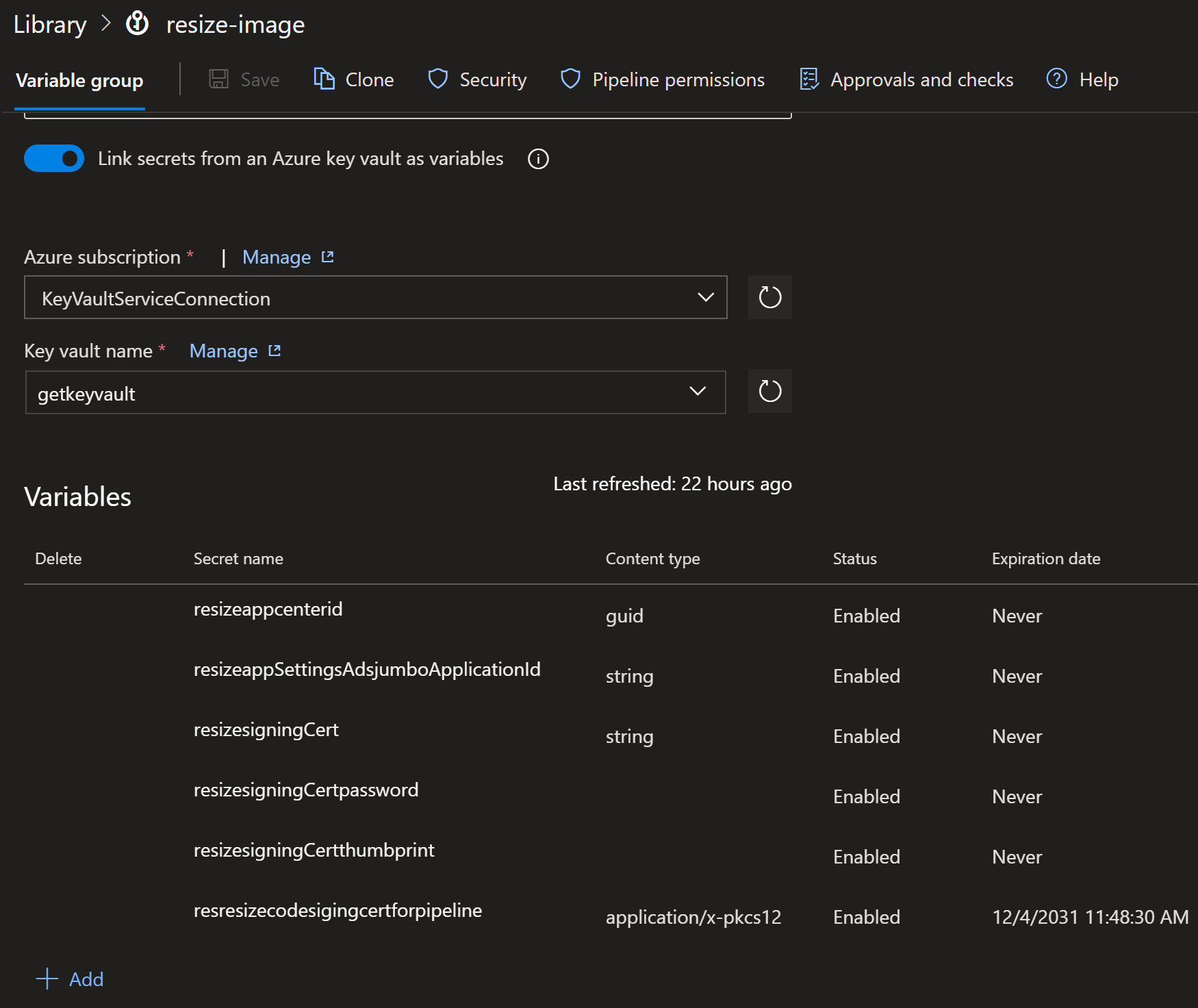
Switching to the Azure Key vault is fairly easy. You only need to
create a new Variable group under Library. I
named the variable group resize-image.Then select
Link secrets from an Azure key vault as variables and
choose the previously created service principal
(AzureDevOpsKeyVaultServiceConnectionsee
here).
Afterwards, enter or select the name of your Azure Key Vault. Then,
click on +Add under the Variables section. A
dialog box will appear, displaying all the secrets and certificates
stored in your key vault. From this list, you can select which secrets
and certificates you want to make accessible under the Variable group
you created.
(Fig 1. variable group)
The next step is to “integrate” the created variable group in the
*.yml pipeline by adding the group
group: resize-image to variables.
[...]variables:-group: resize-image[...]
Now you can access the secret resizeappcenterid with
$(resizeappcenterid). When you try to display the secrets
using echo or a similar command you will only see
*** in order to not be exposed (it’s a security
feature).
Since I needed to sign my code with a certificate I had to adjust the
task which downloaded the certificate from the legacy task
secure files. I didn’t know how to use the certificate
directly from the variable group, so I decided to write a powershell
script which will download the certificate from the azure Key vault and
convert it to a *.pfx file. In the pipeline you need to use the task
AzurePowerShell (Using AzureCLI will not work
as the command Get-AzKeyVaultSecret will result in unknown
cmdlet).
The task itself looks like the following:
-task: AzurePowerShell@5displayName:'Download certificate & install'inputs:azurePowerShellVersion:'LatestVersion'azureSubscription:'KeyVaultServiceConnection'ScriptType:'InlineScript' Inline: | #the name of the key vault $keyvaultname='getkeyvault' #the certificate name $certname="$(resizesigningCert)" #the path to the certificate (required in the next steps) $certFilePath="$(Build.SourcesDirectory)\certName.pfx" #create a pipeline variable so it can be used in the next tasks Write-Host $certFilePath Write-Host "##vso[task.setvariable variable=certFilePath]$certFilePath" Add-Type -AssemblyName System.Security #get certificate from azure #$secret=az keyvault secret show -n $certname --vault-name $keyvaultname $secret = Get-AzKeyVaultSecret -VaultName $keyvaultname -Name $certname #convert secret to byte array $pass = $secret.SecretValue | ConvertFrom-SecureString $bstr = [System.Runtime.InteropServices.Marshal]::SecureStringToBSTR($secret.SecretValue); $PlainTextString = [System.Runtime.InteropServices.Marshal]::PtrToStringAuto($bstr); $secretByte = [Convert]::FromBase64String($PlainTextString) $x509Cert = new-object System.Security.Cryptography.X509Certificates.X509Certificate2 #import certificate $x509Cert.Import($secretByte, "", "Exportable,PersistKeySet") echo "imported" #store the pfx file $exportedpfx=$x509Cert.Export('PFX',"$(resizesigningCertpassword)") Set-Content -Path $certFilePath -Value $exportedpfx -Encoding Byte
The *.pfx file is now ready to use for code signing. In
uwp this can look like the following
When running into problems in the build pipeline always examine the
log and error message and try to reproduce it on your local device using
the powershell command line.